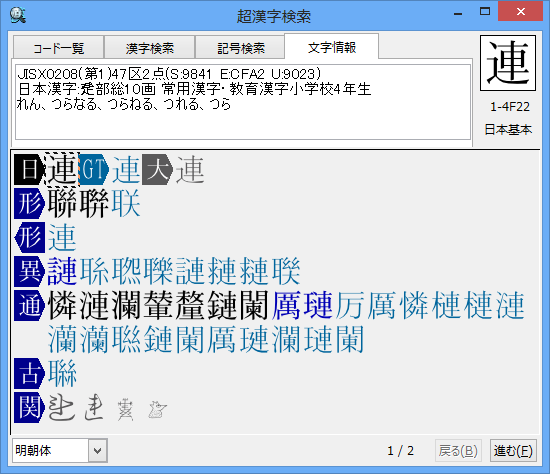
詳細編:文字情報を見る
選択した文字に対して、いろいろな文字情報(文字種、区点番号、大漢和番号、GT書体番号、部首、画数、よみ、同定字、関連字などの情報)を見ることができます。
- 〈コード一覧〉、〈漢字検索〉または〈記号検索〉の見出しで、文字情報を調べたい文字をクリックして選択します。
選択した文字が選択枠で囲まれます。
- 〈文字情報〉の見出しをクリックします。
選択した文字に関する情報が表示されます。
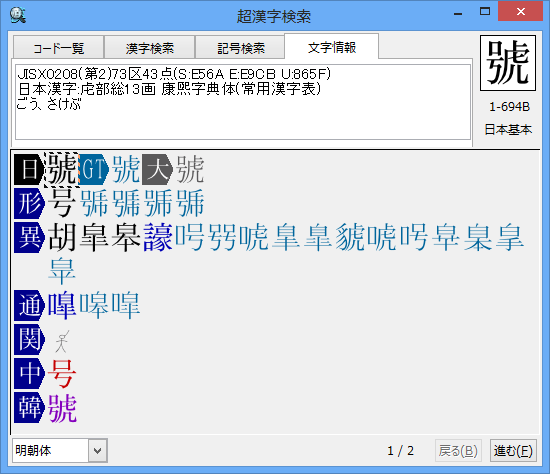
文字コードを区別するために、文字コードの情報には以下の略称が使われます。
| 略称 | 意味 |
|---|---|
| S | Shift JIS(日本) |
| E | EUC(日中韓台) |
| U | Unicode(存在する場合) |
| B | Big5(台湾) |
法令等で定められた漢字表に収録されている漢字は、その属性が表示されます。
| 属性 | 意味 | 法令等 |
|---|---|---|
| 常用漢字 | 常用漢字表に収録されている漢字。 2010年11月30日に平成22年内閣告示第2号「常用漢字表」として内閣告示された。従来の常用漢字表から196字を追加、5字を削除し、2136字からなっている。 |
常用漢字表 (文化庁) |
| 康煕字典体 | 常用漢字に対して、明治以来行われてきた活字の字体とのつながりを示すために参考として添えられている「いわゆる康煕字典体」。 | |
| 教育漢字 (学習漢字) |
常用漢字のうち小学校6年間のうちに学習することが文部科学省によって定められている漢字の総称。 文部科学省による学習指導要領の付録『学年別漢字配当表』によって、学年別に合計1006字が定められている。 |
学年別漢字配当表 (文部科学省) |
| 人名用漢字 | 日本における戸籍に子の名として記載できる漢字のうち、常用漢字に含まれないもの。法務省により「戸籍法施行規則別表第二」として指定されている。別表第二は「一」と「二」に分類されている。 常用漢字表の改正にともない、2010年11月30日に改正され、常用漢字表に追加された129字を削除(うち3字の異体字が別表第二の二へ移動)、常用漢字表から削除された5字を追加し、合計861字となった。 |
戸籍法施行規則別表第二 (法務省) |
| 印刷標準字体 | 2000年12月8日に国語審議会が常用漢字表外の漢字について「字体選択のよりどころ」として一定の方針を示した答申「表外漢字字体表」において、康煕字典に掲げる字体そのものではないが、康煕字典を典拠として作られてきた明治以来の活字字体である「いわゆる康煕字典体」として位置づけられた字体。 | 表外漢字字体表 (文部科学省) |
| 簡易慣用字体 | 表外漢字字体表において、印刷標準字体の簡易字体として印刷標準字体と入れ替えて使用しても支障ないと判断し得る印刷文字字体。 | |
| 許容字体 | 「しんにゅう/しめすへん/しょくへん」に関係する字のうち、「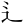 / /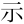 / /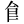 」の字形が印刷標準字体(通用字体)の場合に併記された「 」の字形が印刷標準字体(通用字体)の場合に併記された「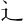 / /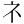 / /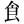 」の字形(3部首許容)。印刷文字として許容字体が用いられている場合には通用字体に改める必要はない。 」の字形(3部首許容)。印刷文字として許容字体が用いられている場合には通用字体に改める必要はない。常用漢字表では、 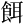 / /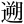 / /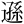 / /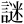 / /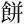 の5字が許容字体とされている。 の5字が許容字体とされている。 |
†文字情報に「常用漢字※」および「許容字体」と表示されるJIS第1水準の漢字は、Windows 8/7/Vistaで[貼り付け]すると、字形が変わる場合があります。
〈文字情報〉の見出しの直下の情報表示エリアで右クリックすると以下のメニューが現れます。
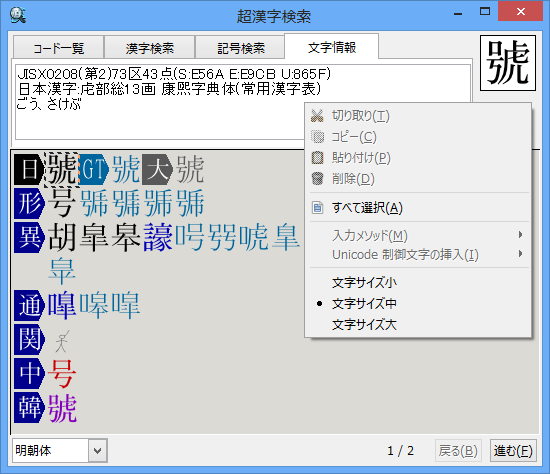
- 全て選択
-
情報表示エリア内の文字列をすべて選択状態にします。
- コピー
-
情報表示エリア内の文字列を選択してクリップボードにコピーできます。
- 文字サイズ 小/文字サイズ 中/文字サイズ 大
-
表示する文字サイズを小、中、大に切り替えることができます。
文字情報の1段目には同定字の一覧が、文字情報の2段目以降には関連字の情報が現れます。
†同定字とは、みかけ上おなじ形をした文字のことです。
†関連字とは、意味や字体などが互いに関連している文字のことです。
†文字情報一覧にある文字をダブルクリックすると、その文字について新規に文字情報を検索します。
文字情報には、それぞれの文字情報の意味を示す、以下のようなピクトグラムが使われます。
| 文字色 | 文字の種類 |
|---|---|
 | 日本基本(JIS第1・第2水準) |
 | 日本補助 |
 | 日本基本(JIS第3水準) |
 | 日本基本(JIS第4水準) |
 | GT |
 | 大漢和 |
 | 中国 |
 | 韓国 |
 | 台湾 |
 | 各国 |
 | iモード/六点点字/八点点字/その他 |
| ピクトグラム | 文字の種類 |
|---|---|
 |
大文字:アルファベットの大文字と小文字の関係における、大文字 |
 |
小文字:アルファベットの小文字と大文字の関係における、小文字 |
 |
関連字:意味や字体が広く関連する文字・記号類どうしの関係 |
 |
異体字:意味や字体、発音などが関連する漢字・文字どうしの関係 |
 |
日本漢字:中国・韓国・台湾の漢字に対する日本の漢字 |
 |
中国漢字:日本・韓国・台湾の漢字に対する中国の漢字(簡体字) |
 |
韓国漢字:日本・中国・台湾の漢字に対する韓国の漢字 |
 |
台湾漢字:日本・中国・韓国の漢字に対する台湾の漢字(伝統字) |
 |
略字:点画を省いて簡略にした字体と、その元になったとされる漢字 |
 |
古字:魯の恭王が孔子の旧宅を壊したときに出てきたとされる字体と、そこから派生した漢字 |
 |
本字:漢和辞典で親字として掲載される字体と、現在一般的に使われている字体 |
 |
篆字:てんじ。前三世紀ごろに中国で使われていた字体と、そこから派生した漢字 |
 |
籀字:ちゅうじ。周王朝の史官が作ったとされる字体と、そこから派生した漢字 |
 |
隷字:れいじ。篆字を省略した字体と、その元になったとされる漢字 |
 |
異形字:特定のパターンで変形した漢字や、インド系文字の字形変化 |
 |
通用字:意味や読み上で交換が行われる漢字どうしの関係。また、日常的に使われている漢字や誤って定着した字体とその元になったとされる漢字 |
†右向きのピクトグラム は親字(文字表示エリアの文字)に対してその関係で派生した文字をあらわし、左向きのピクトグラム
は親字(文字表示エリアの文字)に対してその関係で派生した文字をあらわし、左向きのピクトグラム は、その関係で派生した結果が親字となるような、派生元の文字を表します。たとえば、親字Aに対してBと表示される文字は、親字Aの異形字として文字Bがあるという意味であり、親字Aに対してCと表示される文字は、文字Cの異形字が親字Aとなるという意味です。
は、その関係で派生した結果が親字となるような、派生元の文字を表します。たとえば、親字Aに対してBと表示される文字は、親字Aの異形字として文字Bがあるという意味であり、親字Aに対してCと表示される文字は、文字Cの異形字が親字Aとなるという意味です。
文字情報を調べる
アプリケーション内で表示されている文字の情報を調べることができます。
- 調べたい文字をあらかじめクリップボードにコピーします。
†クリップボードへ文字をコピーする操作はアプリケーションによって異なります。たとえば、右クリックメニューの[コピー]を選びます。
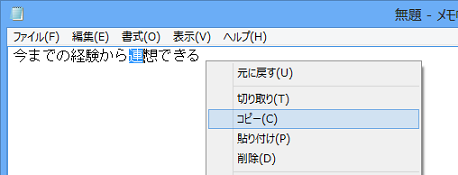
- 超漢字検索の〈文字情報〉の見出しをクリックし、マウスポインタを文字一覧エリアにあわせ、右クリックメニューの[貼り付け]を選びます。
その文字に関する文字情報が表示されます。
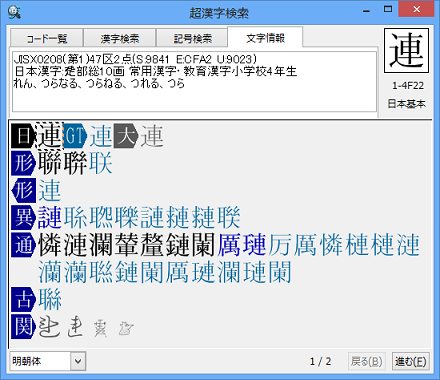
†アプリケーション内に表示された&T形式のTRONコードをクリップボードにコピーし、超漢字検索に貼り付けても、その文字の情報を調べることができます。
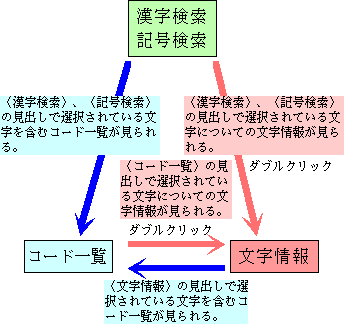
それぞれの見出し間の関係
〈コード一覧〉、〈漢字検索〉、〈記号検索〉、および〈文字情報〉の見出しで、文字を選択して別の見出しに移動したときの動作は、次のようになります。
- 〈漢字検索〉、〈記号検索〉、または〈文字情報〉から〈コード一覧〉への移動
-
選択された文字を含むコード一覧が現れます。
- 〈漢字検索〉、〈記号検索〉、および〈コード一覧〉から〈文字情報〉への移動
-
選択された文字に関する文字情報が現れます。