2020年12月7日
ニューノーマル時代の脱《紙文書》を大幅に効率化
パーソナルメディアが「超漢字検索winMJ」を新発売
~ Web画面の入力時に読めない漢字や異体字をすばやく検索 ~
ソフトウェアメーカーのパーソナルメディア株式会社(代表取締役:松為彰、本社:東京、電話:03-5749-4933、資本金 1,000万円)は、約5万字(*1)の読めない漢字や異体字をすばやく検索してWebアプリに入力できる文字検索ツール「超漢字検索winMJ」(*2)を開発し、業務用のソフトウェアパッケージ(*3)として2021年3月1日から発売開始いたします。また、12月9日(水)~11日(金)に東京ミッドタウンで開催される「2020 TRON Symposium(TRONSHOW)」の当社ブース(ブース番号:A-3)にて、本製品のデモンストレーションを行います。
昨今のWithコロナ時代においては、物理的な接触を避けるという観点から、従来のような紙の文書の利用が見直され、文書のペーパーレス化やオンライン化がますます進んでいます。それに加えて、デジタル庁の創設やマイナンバーの有効活用といった時代の流れにより、電子政府に関連した文書を扱う場面も増えてきました。この傾向は今後もますます加速し、デジタル化やオンライン化による文書処理の効率向上がさらに進むものと考えられます。
しかしながら、人の氏名などに出てくる難しい漢字や読めない漢字の入力作業は、紙文書のオンライン化に対する一つの障壁となっています。紙への手書きの場合は、読めない漢字でも元の字を真似て書くことができますが、端末の画面から漢字を入力するには、何らかの方法でその漢字を特定する、すなわち検索する必要があります。これが日常生活でよく使われる漢字であれば、かな漢字変換などで簡単に入力できますし、WindowsのIMEパッドの手書き入力のような方法もありますが、読めない漢字はかな漢字変換で入力できませんし、字形のわずかに異なる異体字を手書き入力で認識させることも困難です。人名用の異体字には、「渡邊」「渡邉」の「邊」や「邉」(*4)、「斎藤」「斉藤」の「斎」や「斉」のように、多くの異体字を持つ漢字があり、これらの異体字を区別して特定し、画面に入力する必要があります。
このような漢字入力の問題を解決するソフトウェアが、パーソナルメディアの開発した総合文字検索ツール「超漢字検索」です。「超漢字検索」の最初のバージョンは2007年に開発され、これまでWindows用、Android用、iOS用を合わせて10万人以上のお客様にご利用いただいてきました。「超漢字検索」では、漢字の構成部品やカタカナ、異体字などを使った直感的で分かりやすい漢字検索機能により、読めない漢字もすばやく見つけて画面に入力できます。たとえば、「示 メ」のように構成部品の一部をカタカナで表現して「禰」を探したり、「馬×3」のように掛け算を使った検索条件を指定して「驫」や「䯂」を探すことができます。また、Unicode IVS/IVD(*5)に対応した強力な異体字データベースを備えており、利用頻度の低い異体字の細かい字形の差異もきちんと区別しつつ、Unicodeで表現された文字データとしてWebアプリに入力することが可能です。
今回パーソナルメディアが発売する「超漢字検索winMJ」は、この「超漢字検索」のWebアプリ入力対応版です。漢字検索パネルの表示や操作、超漢字検索サーバーとの通信(*6)を行うJavaScriptのプログラムがサンプルとして提供され、それをお客様のWebアプリに組み込むことで、Webアプリのテキスト入力画面における漢字検索を容易に実現します。本ソフトウェアの利用により、ニューノーマル時代の名簿管理などの業務における人名用漢字の入力作業が大幅に効率化できます。
パーソナルメディアでは、本製品および既存の超漢字検索関連製品に加えて、お客様のご要望に応じた多様な漢字ソリューションを提供することにより、新しい時代における文書のペーパーレス化や漢字文化のデジタルトランスフォーメーション(DX: Digital transformation)に貢献していく所存です。
- (*1)
- 「IPAmj明朝フォント」には、58,843字の漢字が含まれます。2021年3月1日に発売する「超漢字検索winMJ」では、このうちの51,760字に対応しており、その後のバージョンアップにより対応文字数を増やしていく予定です。
- (*2)
- winMJ は Web input support for MojiJohokiban の意味です。
- (*3)
- ご提供するソフトウェアには、イントラネット向けの超漢字検索サーバーと、Web入力用フロントエンドのサンプルプログラムが含まれます。システム全体をクラウド上に置くことが可能です。
- (*4)
- 「IPAmj明朝フォント」で字形が区別される「辺」「邊」「邉」の異体字は、合わせて約40文字あります。
- (*5)
- Unicode IVS/IVDとは、Unicodeにおいて漢字の異体字をコード化して扱うための規格です。異体字を示す字形の一覧がIVD(Ideographic Variation Database: 漢字字形データベース)として登録、公開されており、テキストデータ中の異体字の区別をIVS(Ideographic Variation Sequence: 異体字シーケンス)によって指定します。IVDには、文字情報基盤に対応した "Moji_Joho" などのコレクションが登録されています。
- (*6)
- 漢字検索の処理部分や漢字のデータベースは、ネットワーク接続されたサーバー(超漢字検索サーバー)に置かれており、それをJavaScriptのフロントエンドからWebAPI(*7)を経由して呼び出します。このため、端末側には漢字検索の負荷がかかりません。漢字検索のWebAPIとしては、「超漢字検索 Web版」として開発した技術を使っています。
- (*7)
- ウェブサイトやWebアプリケーションで使用する機能を提供するためのプログラミングインタフェースです。APIはApplication Programming Interfaceの略です。
図表
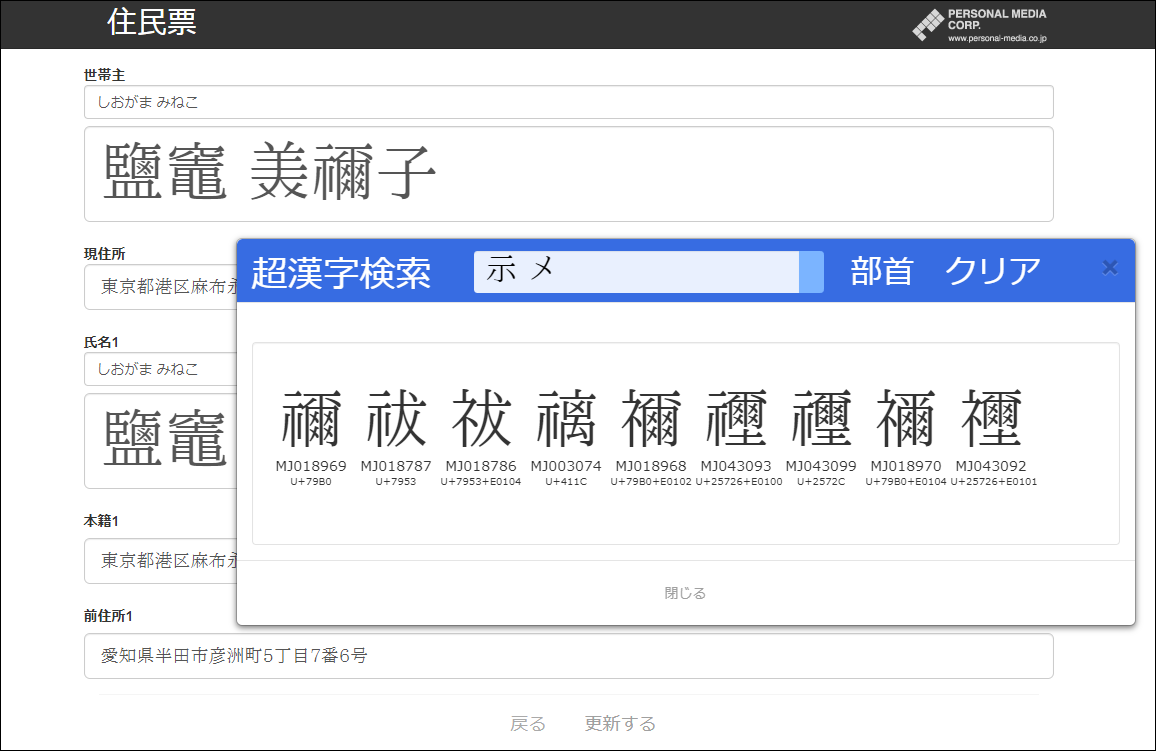
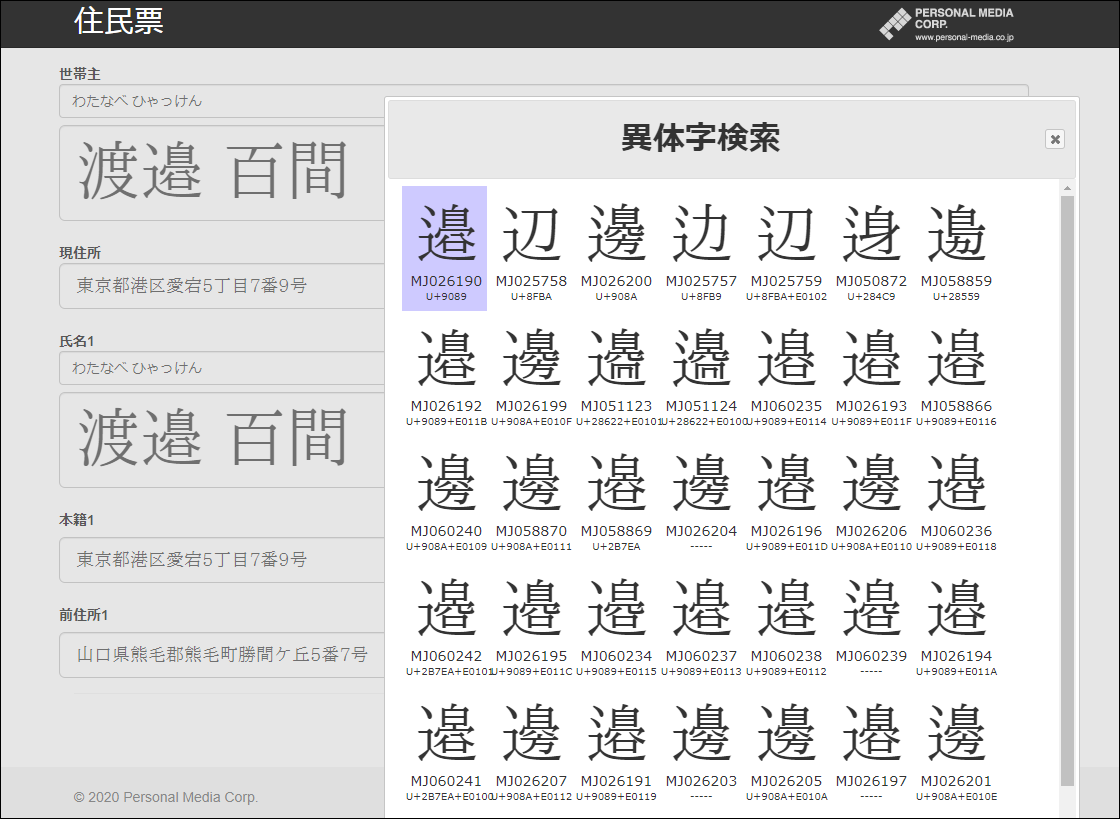
「超漢字検索winMJ」の特長
- 人名用の珍しい漢字や異体字を含めた約5万(*1)の漢字を検索して、住民票や戸籍の管理、会員名簿データベースなどの業務用Webアプリの画面に入力することができます。名簿の作成や電子政府の端末操作などの場面における作業負荷を軽減し、入力ミスを防ぎます。
- 漢字の読みや画数はもちろん、部首や一部の部品、異体字、それらの組み合わせなどを用いた、直感的で分かりやすい操作による漢字の検索が可能です。
- 「IPAmj明朝フォント」と、Unicode IVD の "Moji_Joho" コレクションに対応しており、IVS(*5)を使って異体字の細かい字形の差異を区別します。「IPAmj明朝フォント」は、文字情報基盤整備事業によって開発され、現在は一般社団法人文字情報技術促進協議会が管理している約6万字の業務用の漢字フォントです。人名の表記など、細かな字形の差異を使い分ける場面での利用を想定して開発されており、「戸籍統一文字」の55,270字や「住民基本台帳ネットワークシステム統一文字」の19,563字の漢字を含んでいます。
参考情報、リンク集
- 一般社団法人 文字情報技術促進協議会 (旧: 文字情報技術促進協議会)
- https://moji.or.jp/
- IPAmj明朝フォント
- https://moji.or.jp/mojikiban/font/
- 超漢字検索 Web版
- http://www.chokanji.com/ckk/press_ckkweb.html
- 超漢字検索 文字情報基盤対応版
- http://www.chokanji.com/ckk/ckkmj.html
- 超漢字検索 Windows版、Linux版、iOS版、Android版
- http://www.chokanji.com/ckk/
プレスリリース印刷用PDF
- 超漢字はパーソナルメディア株式会社の商標です。
- 本資料に記載された製品の仕様、画面イメージなどは、発表日現在のものです。最終的に販売される製品では、製品改良などのために変更されることがありますので、あらかじめご了承ください。ご購入の際は、最新情報をご確認ください。